Results
A walk through our findings — click any figure to enlarge
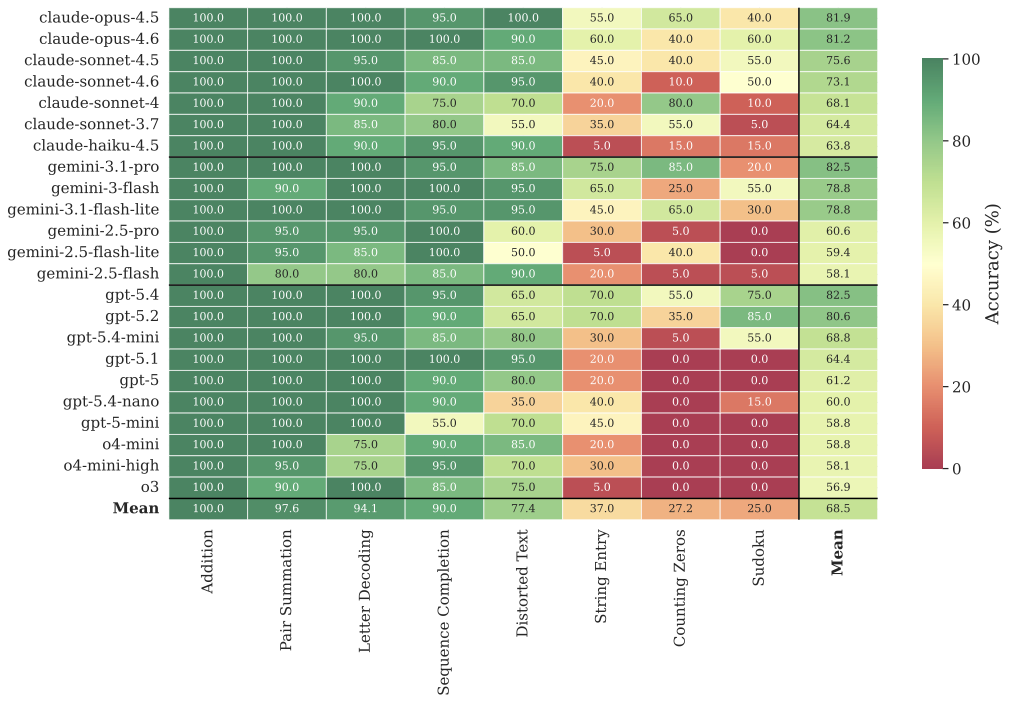
The Big Picture
We tested 23 LLMs from OpenAI, Google, and Anthropic on 8 canonical real-effort tasks. The heatmap tells the story at a glance: most models solve most tasks well, but the picture is far from uniform.
An LLM averaging 80% overall may score near-perfectly on Addition and Pair Summation while failing on Sudoku and Counting Zeros. The best-performing models — GPT-5.4 and Gemini 3.1 Pro — reach 82.5% accuracy, but two tasks remain resistant to automation even at the frontier, creating a sharp diagonal of failure in an otherwise green heatmap.
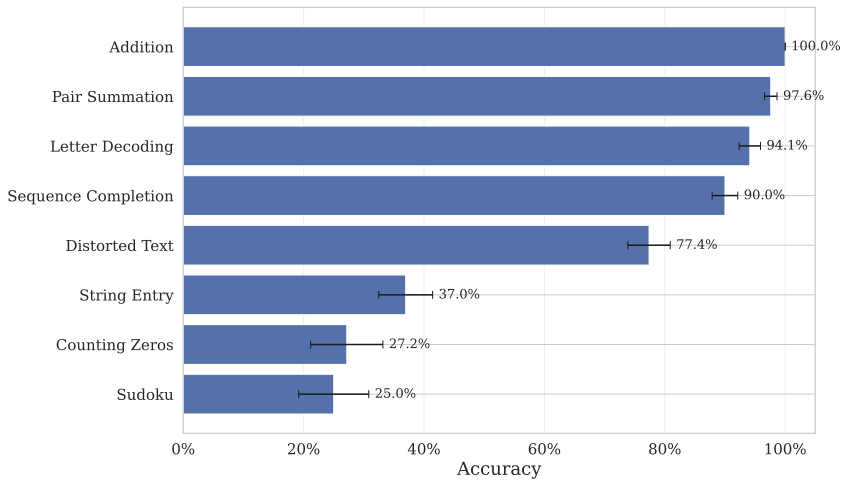
Not All Tasks Are Equal
The difficulty ranking reveals a striking heterogeneity. A model averaging 80% overall may score near-perfectly on Addition while failing completely on Sudoku. This matters for experimental design: the vulnerability of an experiment depends on which task it employs, not just which model a participant might use.
Researchers can exploit this by selecting or combining tasks where LLM performance remains low and variable, rather than relying on a single task whose difficulty may erode with the next model release.
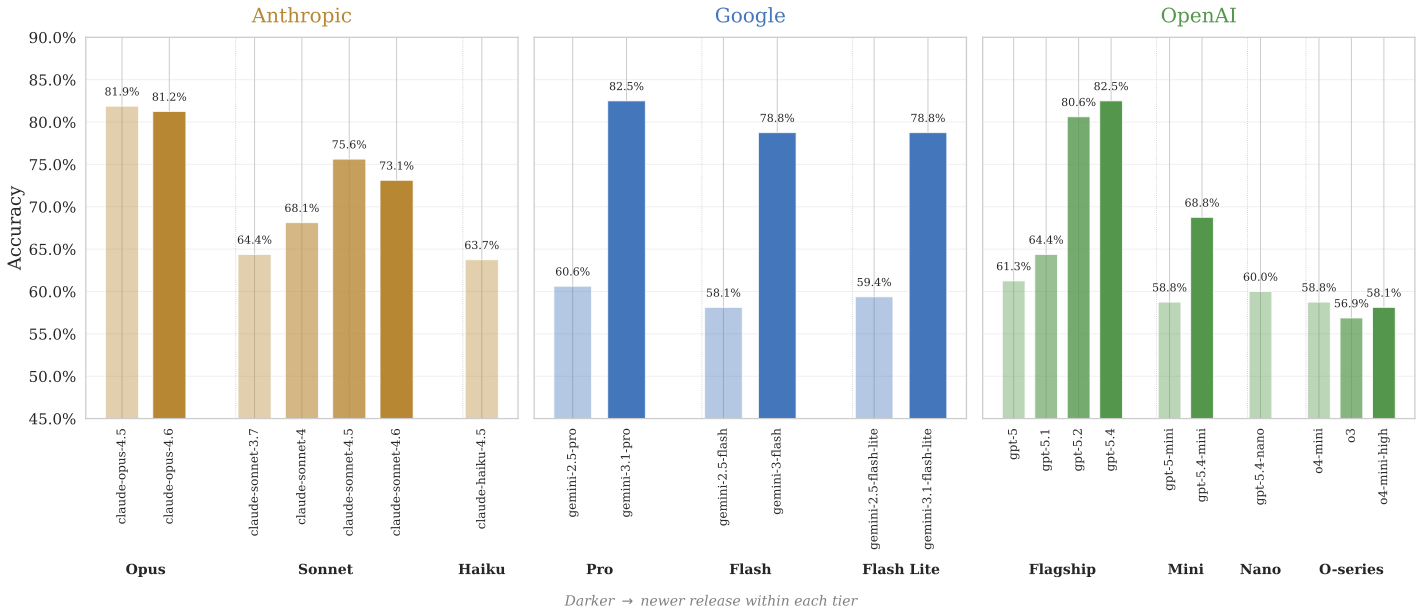
Mid-Tier Is Catching Up
Within each provider family, newer releases almost always outperform older ones — and the largest generational gains are concentrated in the mid-range tier, precisely where cost makes models most accessible to participants.
This means the set of LLMs capable of performing well on real-effort tasks is expanding beyond expensive frontier offerings and into cheaper, more widely accessible ones. The practical barrier to LLM-assisted automation is lowering with every release.
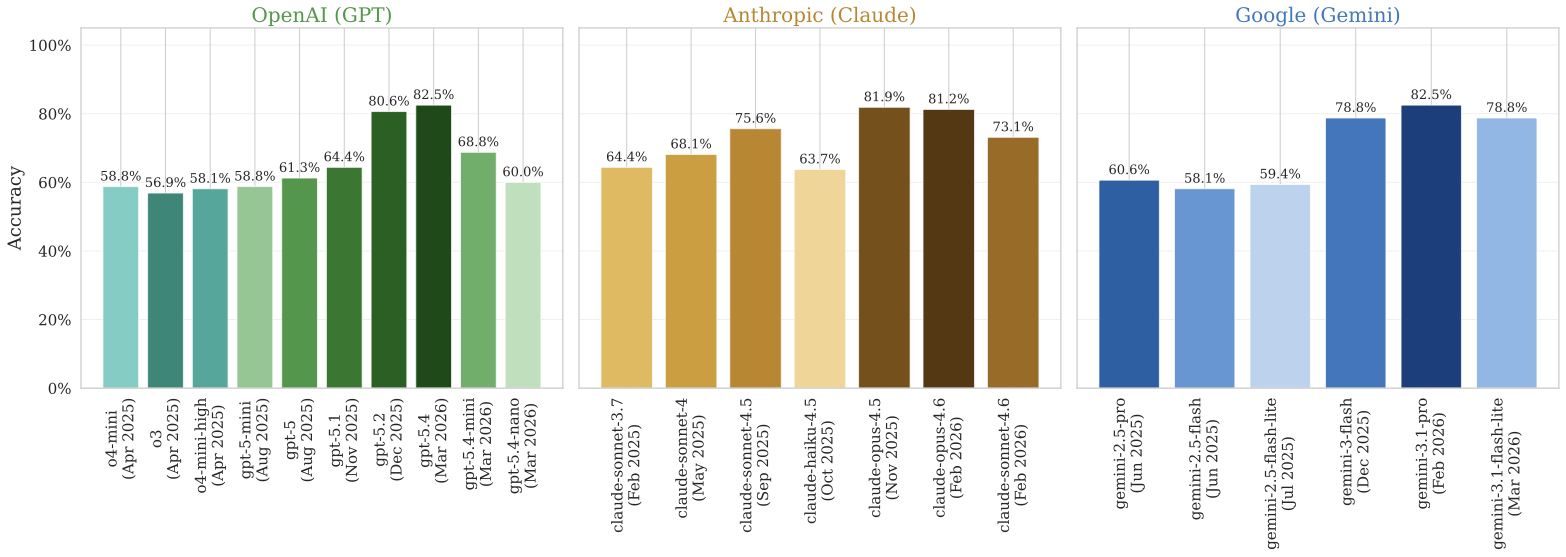
Getting Better, Generation After Generation
Across providers, later versions of a given tier consistently score higher. Gemini Pro improved by 22 percentage points between versions 2.5 and 3.1; GPT-5 gained 21 points from GPT-5 to GPT-5.4; Claude Sonnet improved by 11 points from 3.7 to 4.5 (version 4.6 shows a slight regression).
This upward trajectory implies that, as providers continue to release improved models, tasks that are currently resistant to automation may not remain so for long.
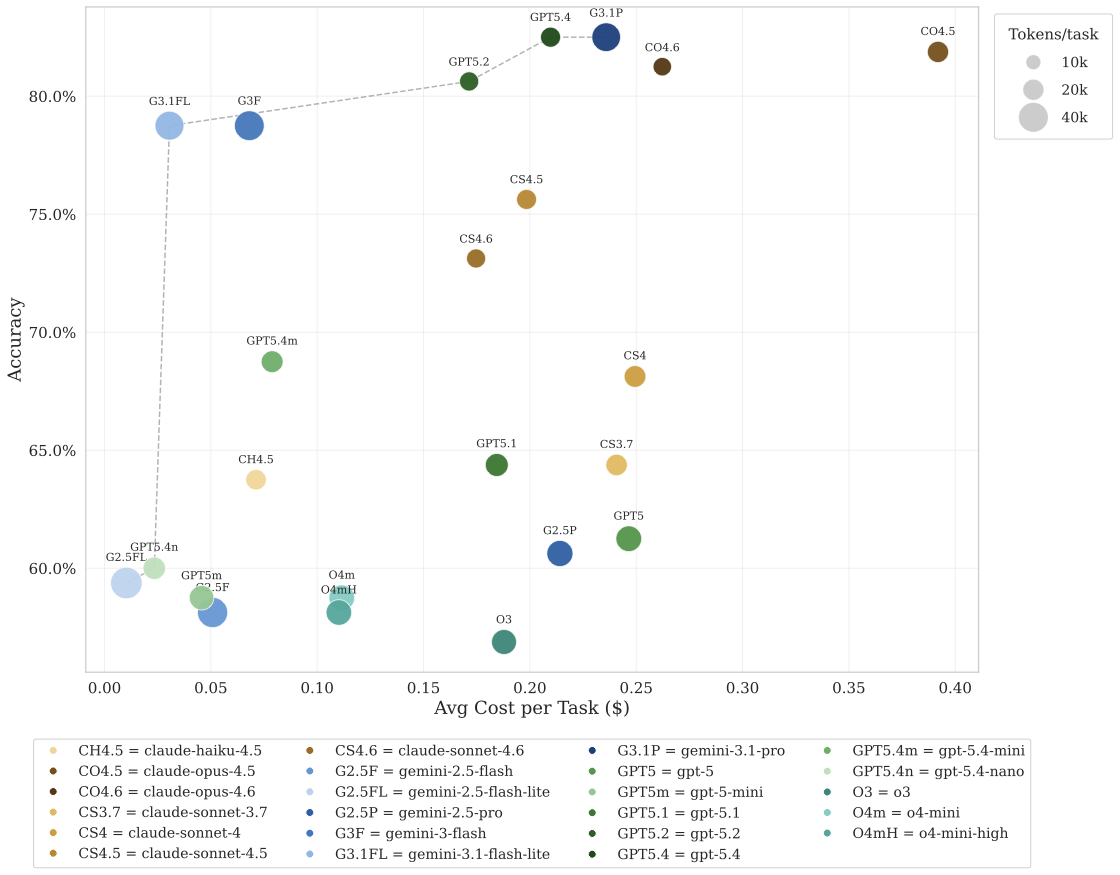
Cheap and Accurate
The bubble chart maps accuracy against cost, with bubble size proportional to the total tokens consumed per task. The best-performing models — GPT-5.4 and Gemini 3.1 Pro — achieve 82.5% accuracy at an average cost below $0.25 per task, a fraction of what a human participant would earn on Prolific or MTurk for an equivalent workload.
Even the cheapest LLMs still reach 58–60% accuracy. Notably, Gemini 3.1 Flash Lite hits 78% accuracy at just $0.03 per task, suggesting that the cost barrier to high-quality automation is already negligible.
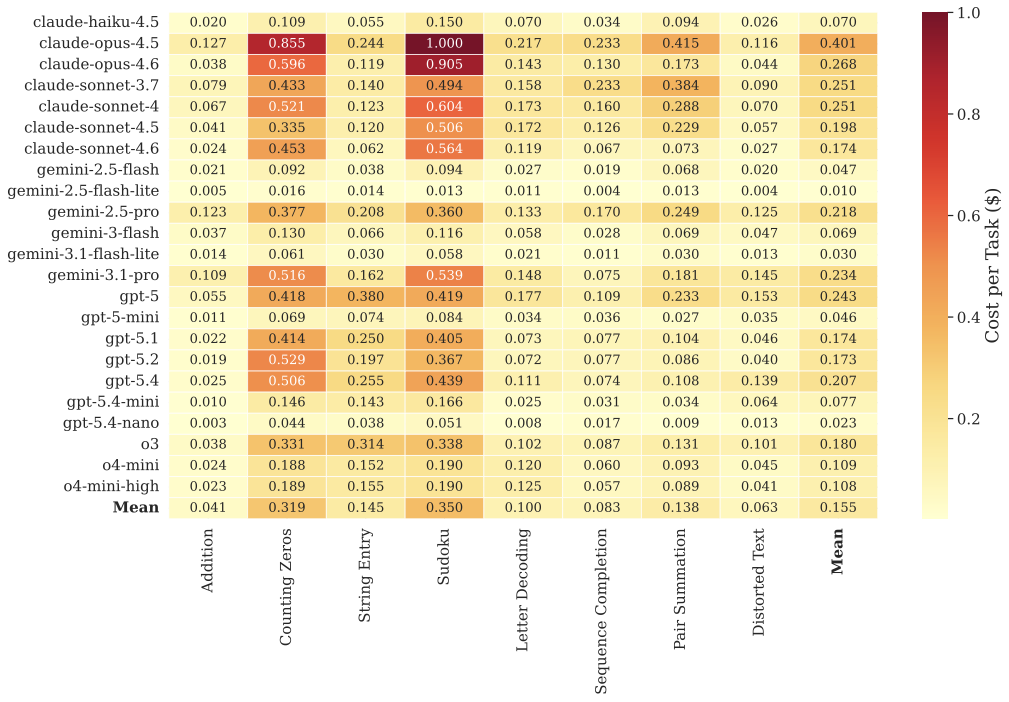
The Economics of Artificial Effort
The cost heatmap breaks down expenditure per model and task. The most expensive model — Claude Opus 4.5 — averages below $0.40 per task (where each task comprises 20 runs). The cheapest models solve tasks at an average cost below $0.05 while still reaching above 60% accuracy.
When the net gain from replacing human effort is consistently positive, the rational incentive for participants in unsupervised experiments is clear. Our findings establish a boundary condition: observed performance in these settings may no longer reflect genuine human effort.

Incentives Don't Move the Needle
We tested five treatment conditions: a control, standard prompts with and without monetary incentives, and human-persona prompts with and without incentives. The per-cell deltas are small in absolute magnitude — the vast majority fall within ±10 percentage points, which for 20 trials corresponds to a difference of at most two correct answers. The distribution of deltas is roughly symmetric around zero.
The sign of the delta is inconsistent within LLMs: a model that shows a positive incentive effect on one task frequently shows a negative effect on another, with no discernible pattern. This is consistent with stochastic response variability rather than a genuine behavioral response — incentive structures designed for humans simply don't apply to LLMs.
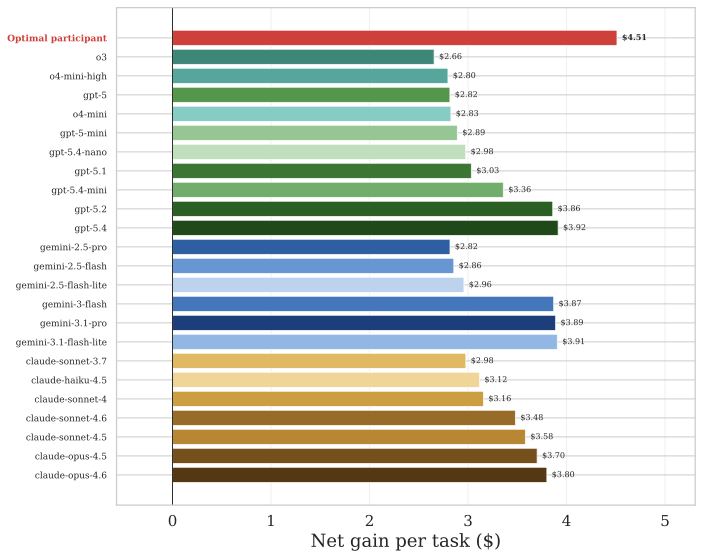
The Net Gain From Outsourcing
Defining net gain per task as the hypothetical payout ($0.25 per correct answer, a conservative estimate of typical online-experiment piece rates) minus LLM cost, every single model generates a positive net value, ranging from $2.66 (o3) to $3.92 (GPT-5.4).
A strategic "optimal participant" who cherry-picks the best model for each task — e.g., Gemini 3.1 Pro for Counting Zeros, GPT-5.2 for Sudoku — reaches 93.1% average accuracy, an 11-point jump over the best single model (82.5%). Even the hardest tasks (Sudoku, Counting Zeros, String Entry) are solved at 75% or above under cherry-picking, yielding a net gain of $4.51 per game.
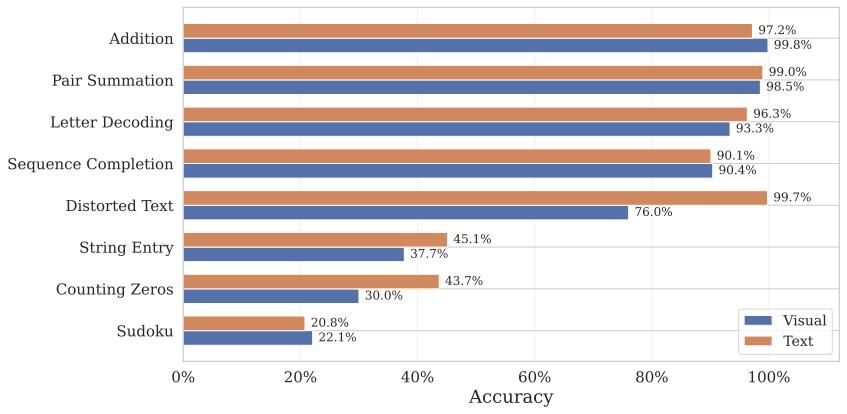
Do Images Make a Difference?
Some tasks present information as images (grids, puzzles) while others use plain text. We compared LLM performance across these modalities. The gap exists but is narrower than expected — modern multimodal models handle visual inputs well, though text-based presentations still have a slight edge.
This suggests that making tasks image-heavy is not, by itself, a sufficient defense against LLM automation. Vision capabilities are improving rapidly, and the image-text gap is closing with each model generation.
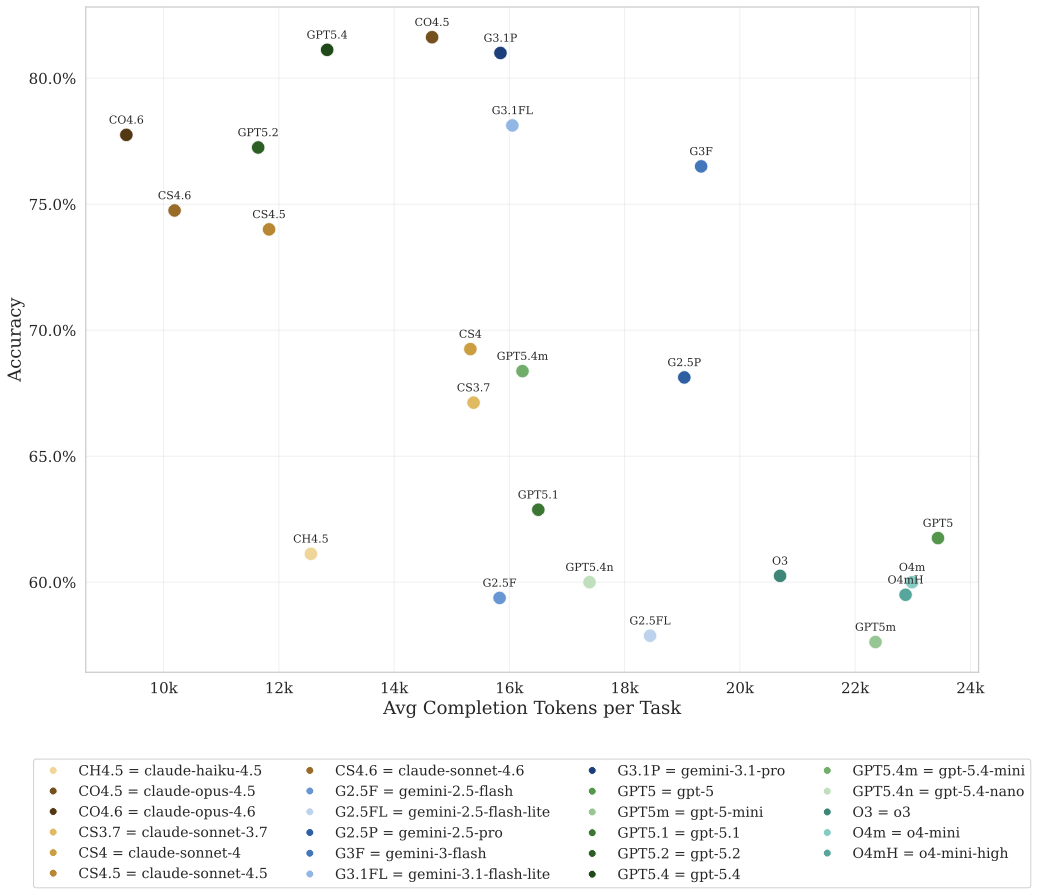
More Tokens, Better Answers?
A natural question is whether models that produce longer responses — using more tokens — tend to be more accurate. Plotting accuracy against average completion tokens per task for each of the 23 LLMs, no clear positive relationship emerges: producing more output tokens does not reliably predict higher accuracy.
Some of the most accurate models are among the most concise. Verbose reasoning does not guarantee correctness — token count is a poor proxy for effort quality.
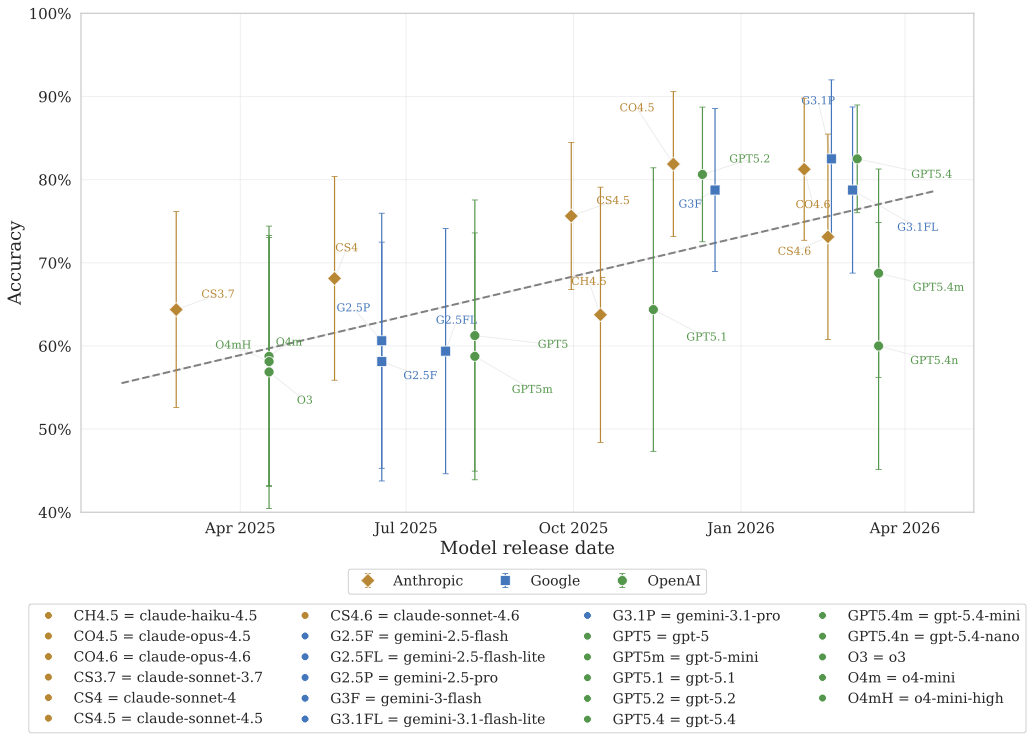
The Trend Is Clear
Plotting accuracy against model release date reveals a clear upward trajectory. Each new generation of models chips away at previously resistant tasks. What was hard last year becomes routine this year.
For experimental economists, this has an unsettling implication: a task battery designed today to be LLM-resistant may not remain so. Continuous monitoring and adaptation of experimental protocols will be necessary as models continue to improve.
Accuracy by Treatment Condition
Detailed heatmaps for each experimental treatment — performance is remarkably stable across conditions
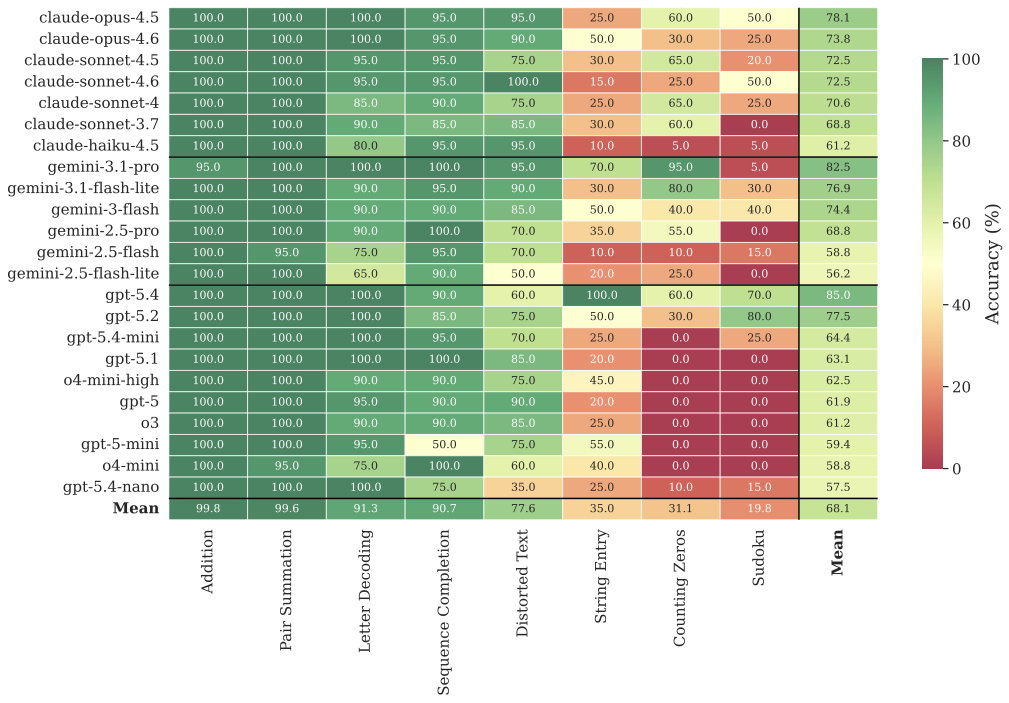
T1: Standard, No Incentive
Accuracy (%) per model and task.
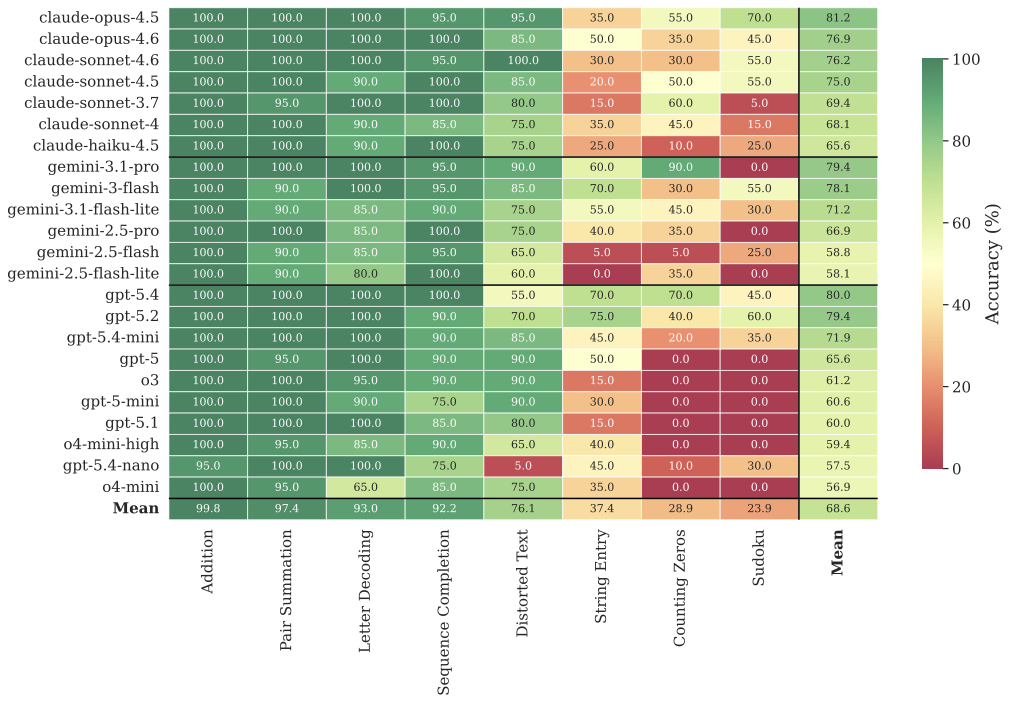
T2: Standard, Incentive
Accuracy (%) per model and task.
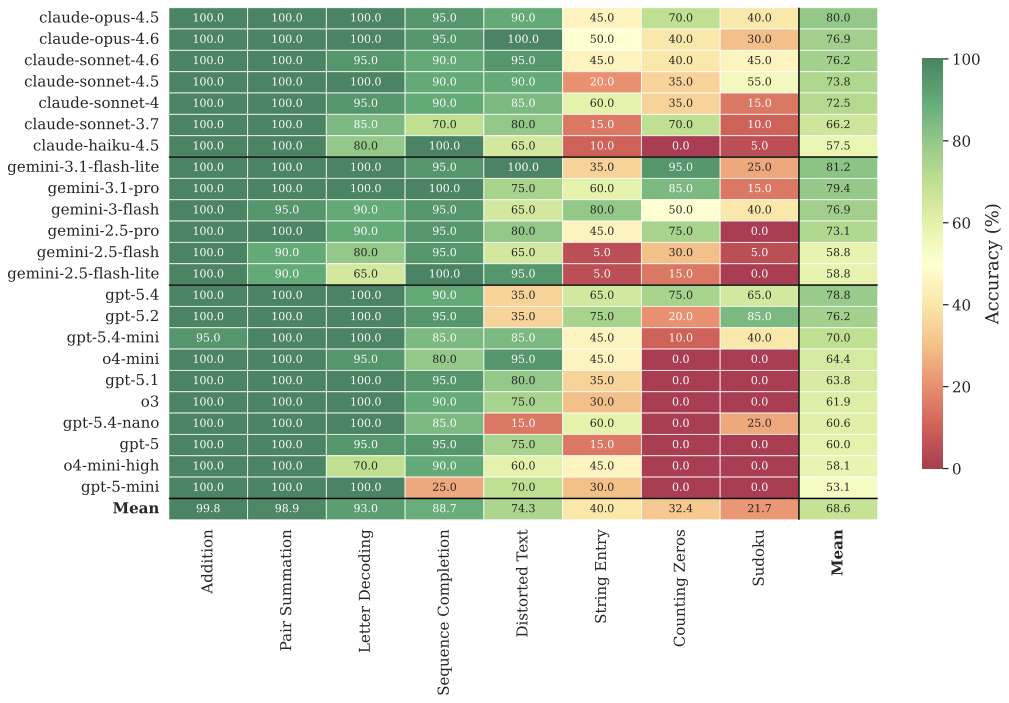
T3: Human, No Incentive
Accuracy (%) per model and task.
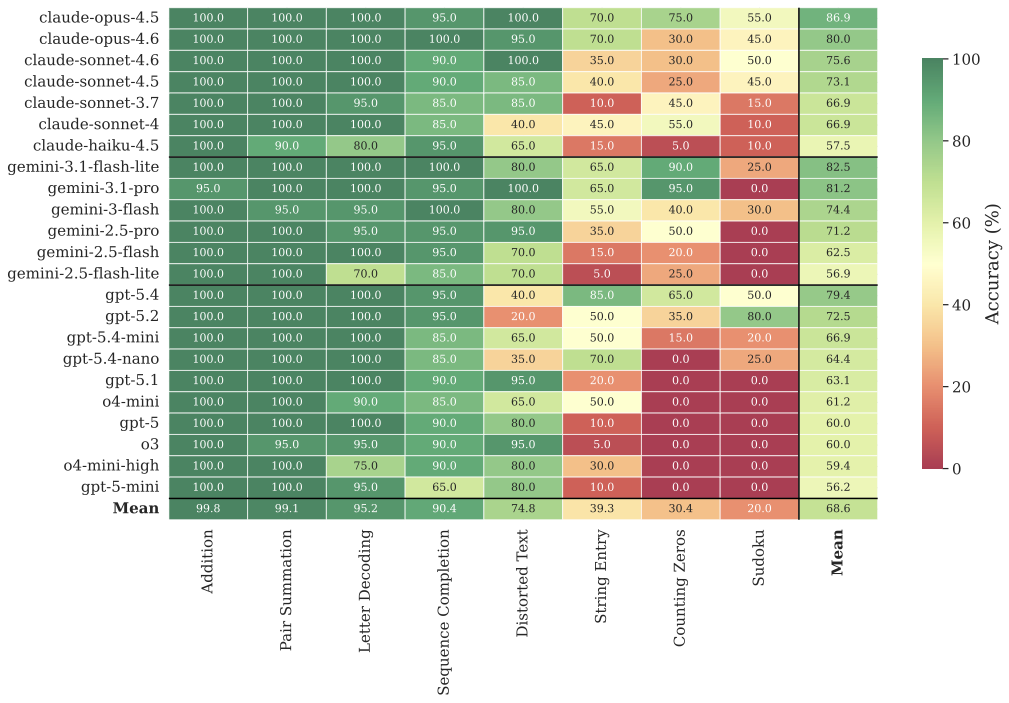
T4: Human, Incentive
Accuracy (%) per model and task.